- Published on
Architecture Patterns
- Authors

- Name
- Ashish Thanki
- @ashish__thanki
This shorts blog post highlights the importance of architecture patterns and points out what should be considered when creating software systems in Python.
When we start a project the code base may look clean and obvious to us on how it is ordered and structured. However, overtime this changes when more code is adapted into, added or even forced in to ensure things work. We even start to see additional classes, and util modules being created to make things work. The architecture that was once present has long been collapsed and adding additional features may not be apparent.
All these problems can be avoided with correct implementation of architecture patterns.
Encapsulation and Abstractions
We first need to start with Encapsulation and Abstraction.
Encapsulation is the process of simplifying behavior and hiding data. We can simplify a process by using an higher level of Abstraction. We have to choose the level of Abstraction as we need to pay attention to the interactions between our objects and functions. When many objects, functions, modules or libraries use each other then we say "one depends on the other". These dependencies can become out of hand and can be visualised using a network or graph, see example below.
Abstractions are simplified interfaces that encapsulate behavior.
Check out this interactive dependency network. The network graph visualizes how python packages depend on each other, each point represents a python package.
SOLID
SOLID is a widely used acronym in software development. It consists of five principles of object oriented design. Single responsibility, Open for extension but closed for modification, Liskov substitution, Interface segregation, and Dependency inversion.
Robert C. Martin’s definition of the Dependency Inversion Principle consists of two parts:
- High level modules should not depend on low level modules. Both should depend on Abstractions.
- Abstractions should not depend on details. Instead, details should depend on Abstractions.
A great example of number 2 can be found on this StackOverflow post. Typically, using an Abstract Base Class is a great way of switching the dependents.
High level modules are the domain specific functions that deal with real-world concepts, meanwhile the low level modules is code that the business does not care about. An example of high level code would be to perform business transformations to data, meanwhile the low level would be to read data from a SQL DB instead of a CSV file. Non-technical stakeholders only care about high level code.
Adding an abstraction between a high level module and low level modules allows us to change either of the modules without having to make changes to the other and becoming more independent of each other. The last thing stakeholders want is changes to business logic being caused by a closely coupled low level read file function. This three-layered architecture is great until the common problem of business logic infecting the three layers making the application hard to identify, understand and change. We must ensure new business logic stays within the business logic layer.
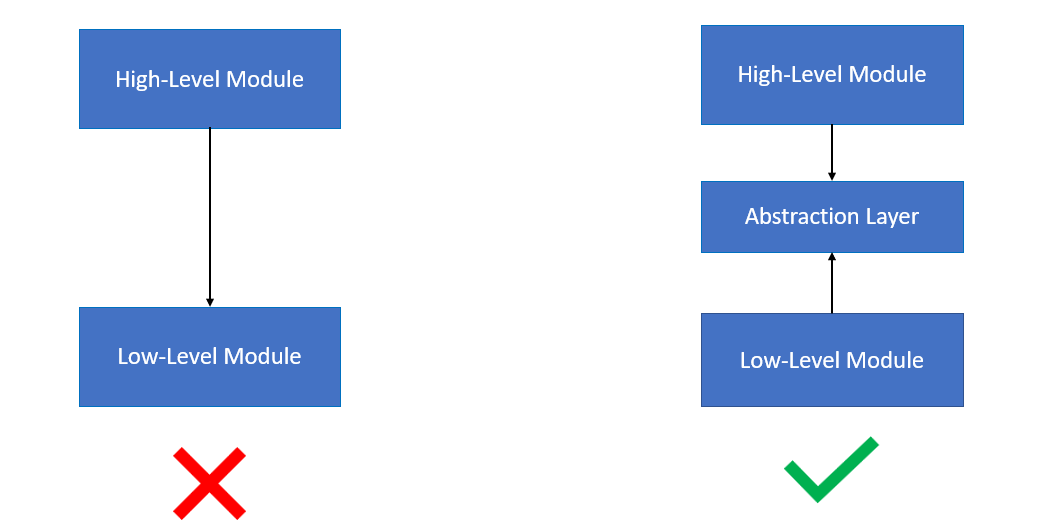
Ensure we continuously apply Dependency Inversion and choosing the right abstractions.
Abstraction and Coupling
When component A of our code is difficult to change because of the fear of breaking component B, we say that the components have become coupled. Local coupling is a good thing because it suggests that the code works well together, as well as support each other, like a fine tuned engine. In technical terms, we would say that there is high cohesion between the coupled elements.
Global coupling is a problem however. When the application grows large then there could be coupling between components which have no cohesion at all. This would make the code extremely difficult to change.
To stop this from happening we can decouple the components by abstracting away the details.
When tests use too many mocks then it implies there is a more coupled implementation which makes the tests more brittle and complicated. These test suites fail to explain the code and are often overwhelmed with setup code that hides what the code is actually doing.
Software Development Process
There are several approaches that can help develop code using the SOLID principles described but two popular approaches I recommend are:
Test-Driven Development: Build code that is correct and enables us to refactor or add new features with regression. The domain model is what we earlier described as business logic layer. A workflow of TDD is before you write any unit of behavior you have a test for this behavior and only this behavior. Only after these tests fail do you implement the behavior.
Domain Driven Design: Focuses on building a good model of the business domain, but can be encumbered with infrastructure concerns and hard to change. DDD is a far more abstract philosophy and set of design patterns that addresses how to design a large, scalable, and maintainable system. Ultimately DDD is about creating a code eco-system that implicitly or explicitly captures important bits of domain knowledge.
Conclusion
Continuously, thinking about the SOLID principles can help numerous data scientists build projects that are maintainable and scalable - a problem amongst us data scientists that do not come from a software background. This makes changes easier as the domain progresses. The domain driven development is useful approach in these scenarios. The TDD approach and DDD are certainly not mutually exclusive and most developers use DDD and TDD together, and I would recommend the same.
Further Reading and Other Tips
Architecture Patterns with Python by Harry Percival and Bob Gregory.