- Published on
Model Drift and Concept Drift
- Authors

- Name
- Ashish Thanki
- @ashish__thanki
Model drift is a silent killer for in-production models and something that data scientists need to be mindful of. The importance of MLOps has been discussed in my previous blog here but model drift requires a lot of upfront thinking and tying in with the wider software developing teams.
Model drift is the occurrence of the deterioration in performance of a machine learning model over time due to underlying changes in the input data distribution. This is commonly referred to as model degradation. Addressing model drift early is crucial in maintaining accuracy and relativity of models in production.
There are several reasons why this happens, it ranges from changes in user behavior to faulty sensors.
There are different types of model drift:
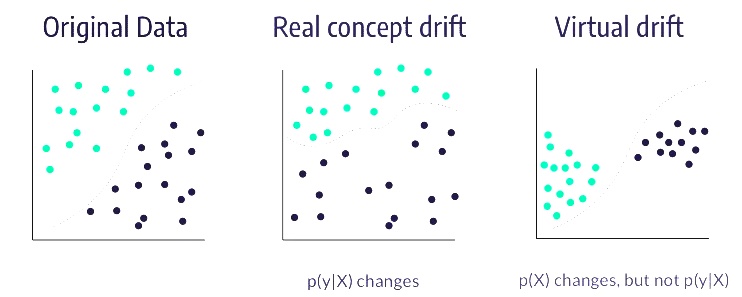
Concept drift: although part of a larger umbrella of various types of drift, it can be summarised as the changes in the underlying pattern in the data which then causes degradation in the model. It occurs when statistical properties of the target variable and the relationship to the feature (or between features!) changes over time. For example, if we gather data using equipment that suddenly becomes faulty then it will impact model performance overtime. The new data no longer reflects the data distribution we previous had. A real life example could be the sudden changes in data during the COVID-19 pandemic.
Hidden context, or virtual drift: when an unmeasured feature affects the prediction. For example, predicting the Earth's temperature would eventually become inaccurate as climate change is the hidden context behind it. Climate change is inaccessible information from the model's view.
Stability–Plasticity Dilemma and Blind Adaptation
When implementing a concept drift handling framework, a system that automatically reacts to the changes in the data stream, we must be aware of the Stability-Plasticity Dilemma. Stability is defined as maintaining relevant and reoccurring knowledge, while plasticity is replacing outdated knowledge in response to the new experience. Ideally, the framework that we enforce should have a balance between these concepts.
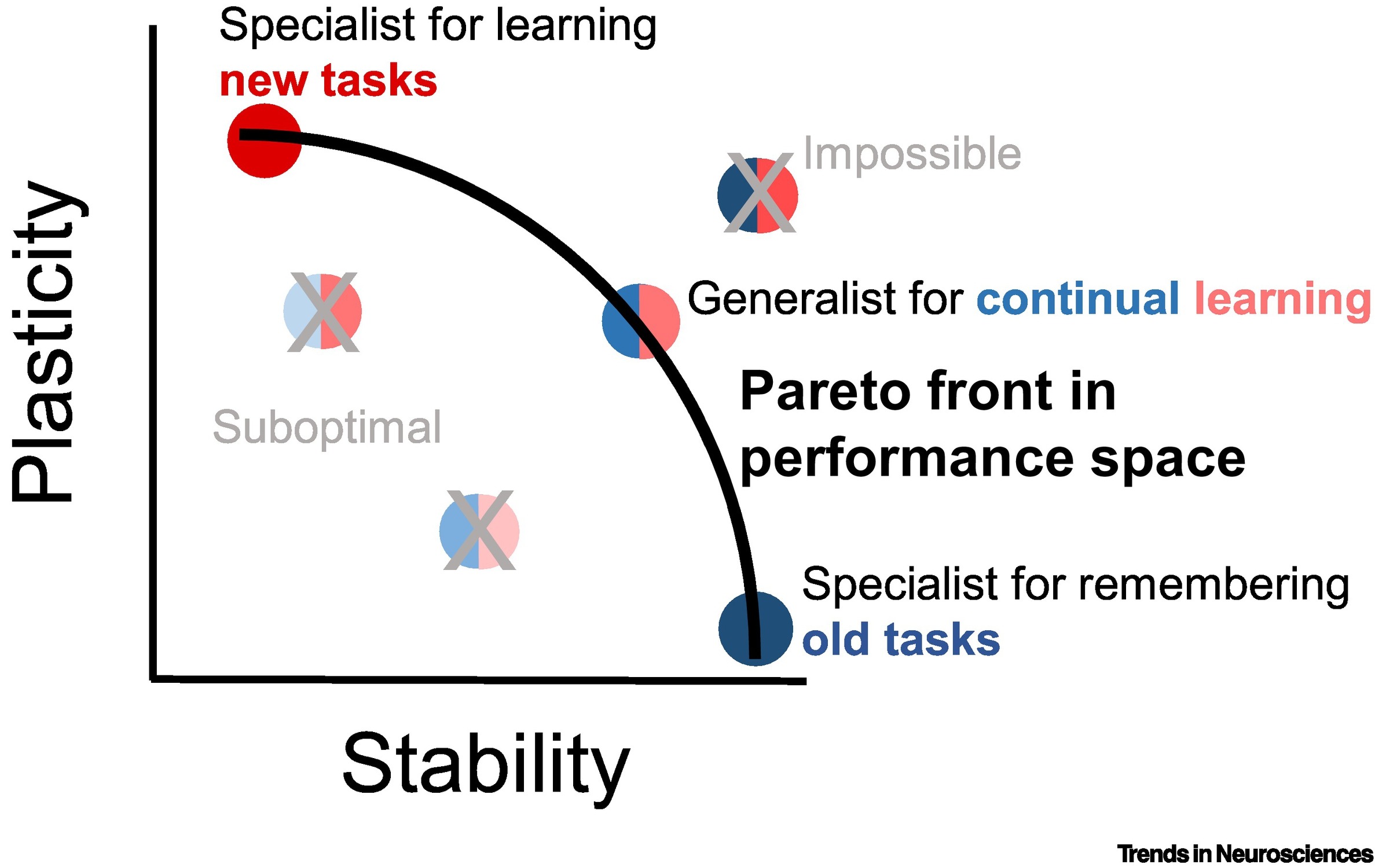
The other strategy is blind adaptation, which is passive approach and is where the model is constantly updated upon new input data instances. This is discussed later.
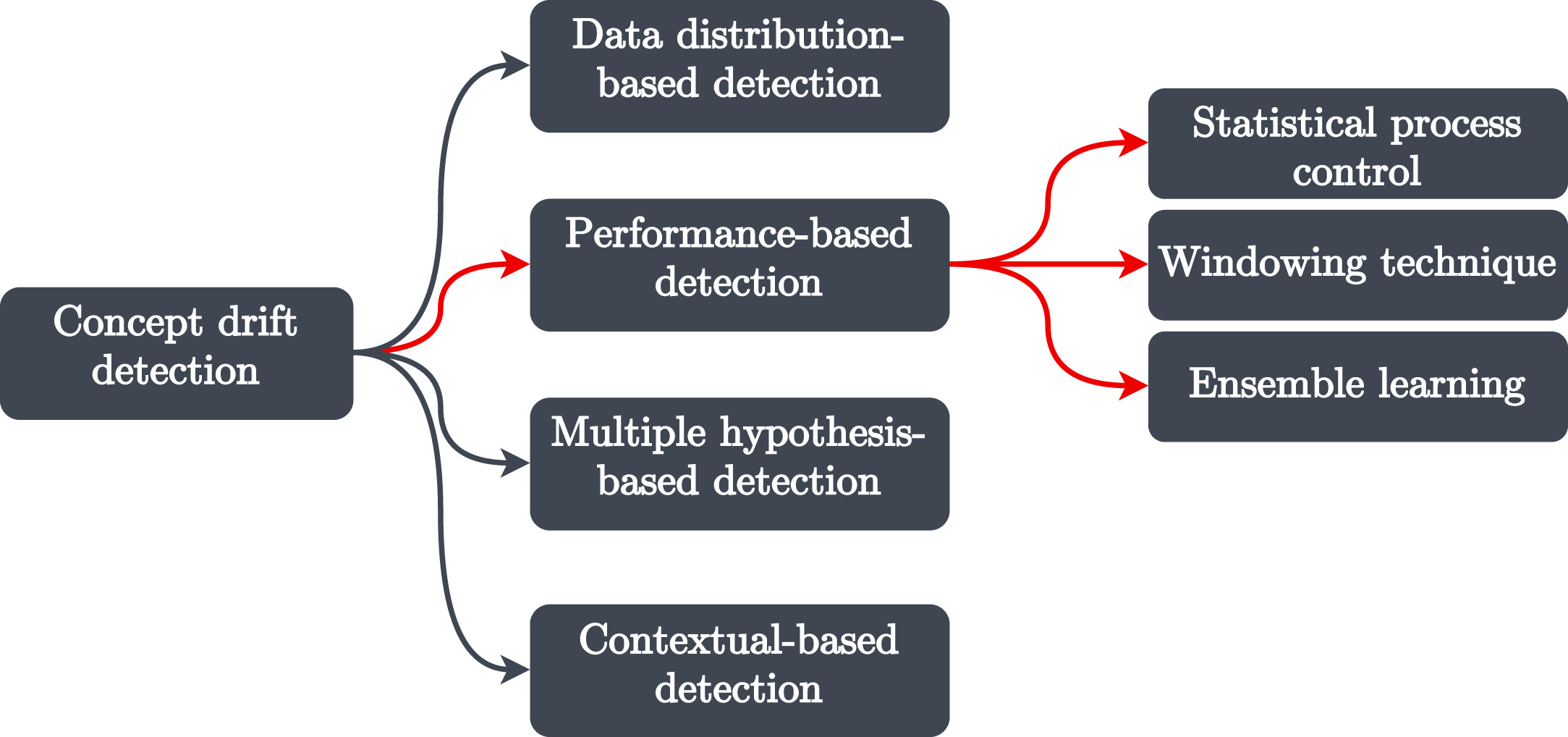
Detecting Concept drift
There is no single God level metric that is used to track drift. We have several options available and it really just depends on the domain.
The typical approach is to utilise test statistic to keep tabs on the data stream and then calculate the statistic against old samples. The value being calculate is then compared against a pre-defined threshold in order to calculate drift magnitude.
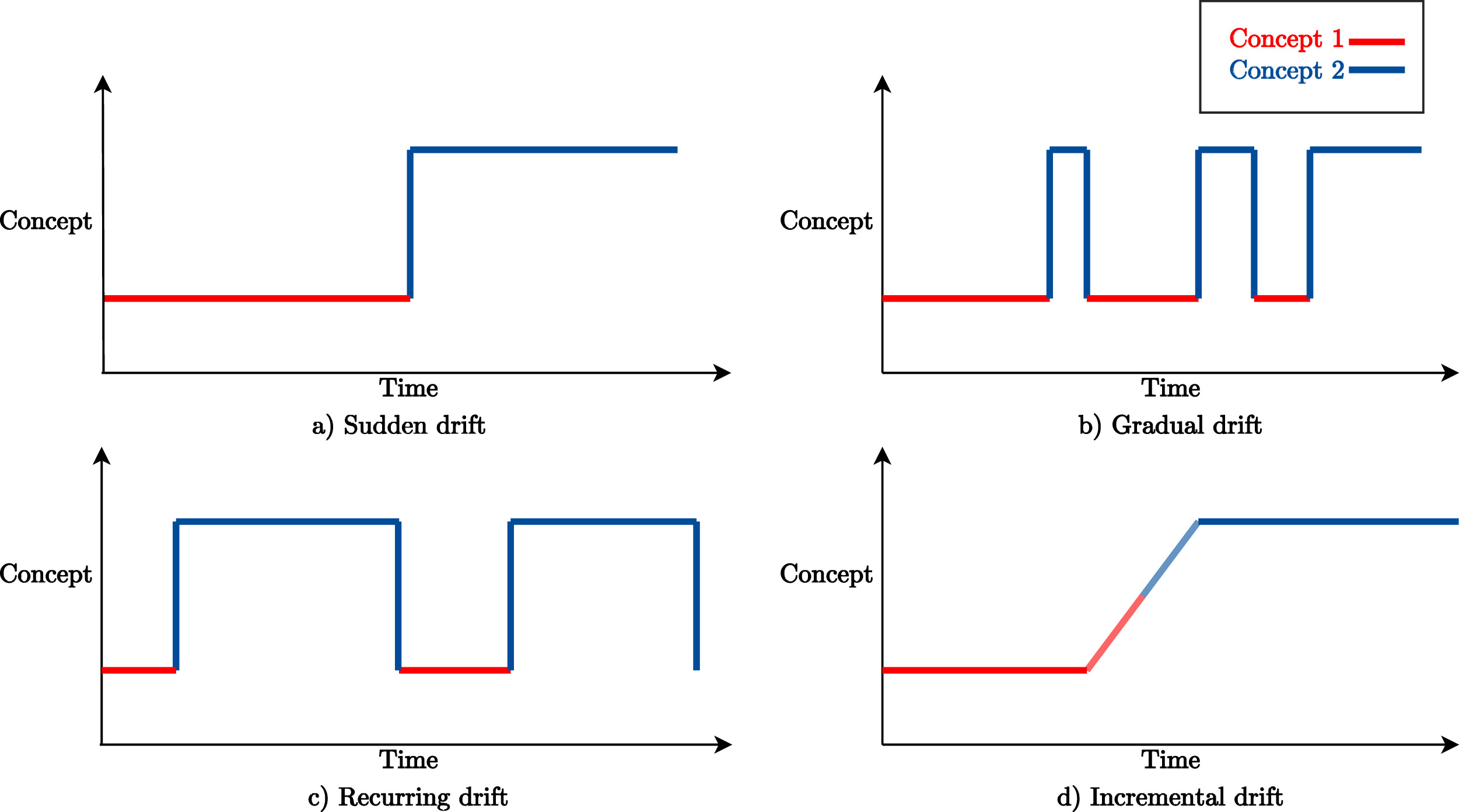
There are many names and terms used in the literature to describe the Concept drift. The popular and widely used terms are sudden, gradual, recurring and incremental drifts but there are many more, see diagram below.
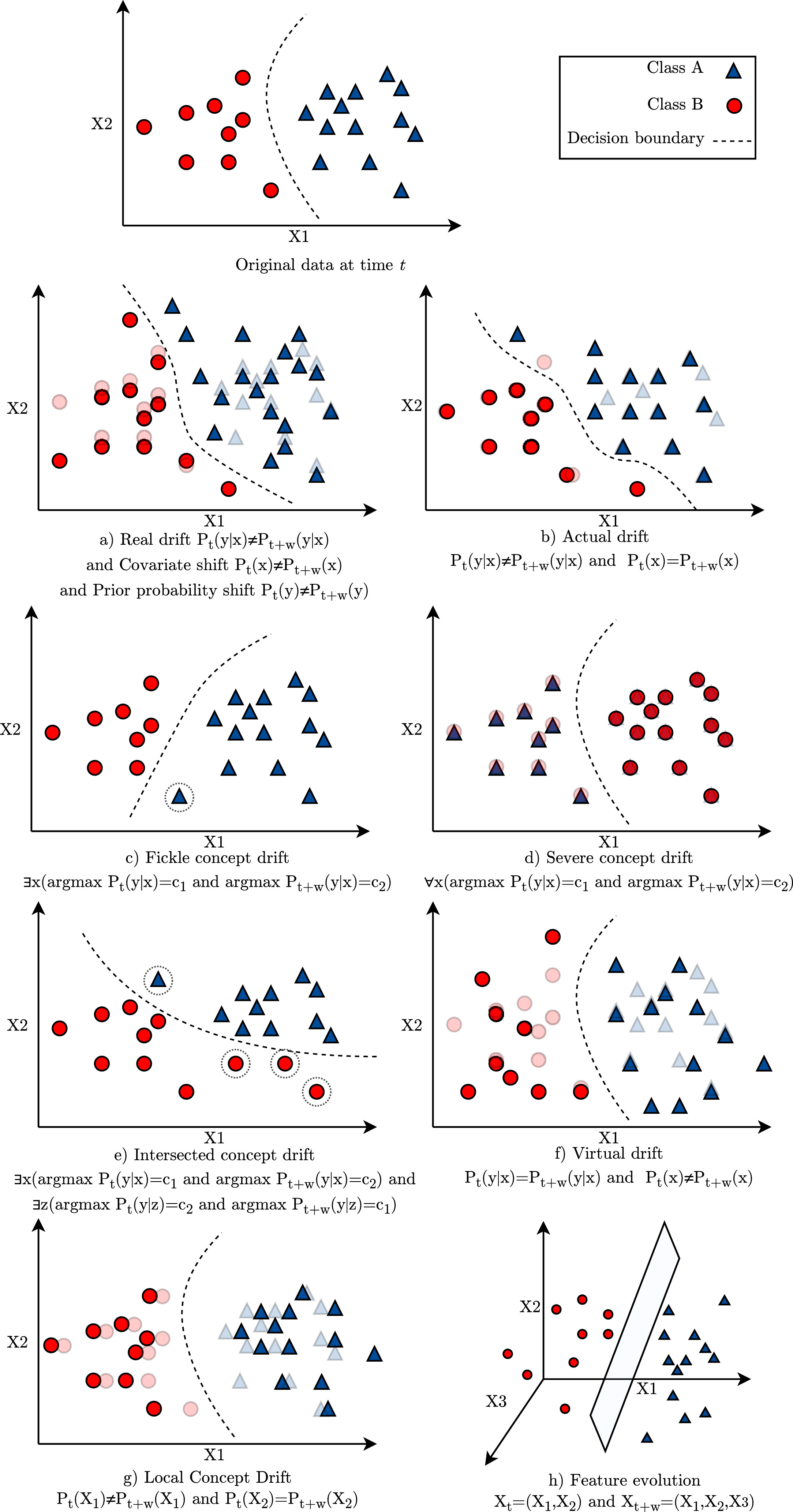
Concept Drift across several applications
There are different applications areas on which concept drift has been recognised and each application requires different adaptations because of their learning tasks. This paper discusses evaluation methodology of adaptive algorithms for various applications in what problems drift can cause and potential solutions. They can be grouped together into the following categories:
Monitoring and Control: time series forecasting and anomaly detection. Concept drift can happen due to short interruptions caused by outage or slower interruptions that can occur overtime perhaps due to a faulty sensor. For example, drift in boiler demand prediction can cause incomplete mixing of fuel. This problem may require ADWIN drift detection.
Management and Strategic Planning: analyse existing data to plan and manage assets. Concept drift may become apparent because of the static nature of the model. For example, if we used existing data to predict wind power it would eventually drift as winds conditions can quickly change and we should opt in online applications instead.
Personal Assistance and Information: recommendation systems and organisation of textual information, customer profiling for marketing,personal mail categorization and spam filtering. Systems that have limited data, for example, users may not classify spam emails for the system so we have fewer recent and relevant training data. This type of drift occurs when content and historically labelled data may not be relevant for the current problem at hand. For example, spam emails change over time or recommendation system may not have the latest trend so concept drift occurs.
We can handle these cases by using content-based filter and learning incrementally so that new data can be used to train our model(s). An ensemble model have had been trained on short-term and long-term interests of users. For example, a stable Naive Bayes classifier is used for modelling the long term interests of a user and the Nearest Neighbour classifier captures the short term interests of the user.
Ubiquitous Environment Applications: moving and stationary systems that interact with the physical changing environment such as autonomous vehicle control. The solution here is to use several data measuring tools such as laser technology to measure short and medium term range for obstacle avoidance and colour camera for drivable surface analysis and velocity control.
Solutions
There are multiple solutions that can address concept drift across these applications, here is a brief list:
- Look back window that only trains over a fixed window size, so that only relevant data is used. This is a first in first out where the first data point is removed first and is abruptly forgotten by the model.
- Flexible look back window that changes over time which is triggered by a change detector (i.e. metric) and dynamically updates this flexible window.
- Retraining the model where the previous parameters are completely discarded, typically, recalling the
fitmethod of a Sci-kit Learn model removes previous parameters learnt. - Incremental training can be used where the current model's weight is updated.
- Online learning updates the current model with the most recent example.
- Model management of ensemble models and ensuring that they are trained on different datasets such as new and old data.
Conclusion
There is no single drift detecting metric or method that works better than all others for all scenarios. You need to try several approaches and speak to domain experts on what quantifies bad model performance or concept drift originating from features or target variables.
The applications highlighted above show that the data scientist needs to understand the source of the drift and then engineer an effective adaptive learning strategy.
Further Reading: