- Published on
Why Data Scientists Should Learn dbt: A Practical Introduction
- Authors

- Name
- Ashish Thanki
- @ashish__thanki
As data scientists, we spend our time building models, running experiments, and generating insights. But behind every successful model is one crucial ingredient: clean, reliable, and well-structured data. Too often, this is where projects stall.
While data engineers or analytics engineers traditionally manage data pipelines, modern teams are becoming more decentralized. This means data scientists are now expected to own more of the data transformation layer themselves.
Enter dbt (data build tool): an open-source framework that allows you to transform raw data using the language you already know—SQL—while incorporating software engineering best practices like version control, testing, and documentation.
What is dbt?
dbt is a development framework for transforming data that has already been loaded into a data warehouse (e.g., BigQuery, Snowflake, Redshift). It doesn't extract or load data; it focuses entirely on the "T" (transformation) in ELT.
With dbt, you can:
- Define data models as modular, reusable SQL
SELECTstatements. - Build and run transformation pipelines with a single command.
- Test data quality to prevent "garbage in, garbage out."
- Generate documentation automatically.
- Visualize dependencies as a Directed Acyclic Graph (DAG).
- Manage everything as code using version control (e.g., Git).
Who Uses dbt?
While dbt is a core tool for Data Engineers and Analytics Engineers, it's becoming essential for Data Scientists and ML Engineers. You'll find it indispensable when:
- Building custom features or complex aggregations for your models.
- Working directly with raw, domain-specific data that requires cleaning and structuring.
- Creating reproducible and testable data pipelines for your experiments.
Getting Started: dbt Core vs. dbt Cloud
You can use dbt in two ways:
- dbt Core: The open-source command-line interface (CLI) tool. It's free, highly customizable, and the focus of this post.
- dbt Cloud: A managed web-based service that provides a development IDE, scheduling, and hosting for your dbt projects.
To start a new project with dbt Core, you run:
$ dbt init my_dbt_project
This scaffolds a standard project structure:
my_dbt_project/
├── models/ # Your SQL transformation logic lives here
├── tests/ # Custom data tests
├── seeds/ # CSV files to load static data
├── snapshots/ # For tracking changes in data over time
└── dbt_project.yml # The main configuration file for your project
What is a dbt Model?
In dbt, a "model" is not a machine learning model. A dbt model is a single .sql file containing one SELECT statement.
When you execute dbt run, dbt materializes this query into a view or table inside your data warehouse.
This simple concept is powerful because it allows you to break down complex transformations into small, manageable steps. For example, you can reference other models using the {{ ref() }} function, creating a dependency chain.
-- models/marts/customer_orders.sql
-- This model aggregates order data to the customer level.
-- It depends on a staging model called 'stg_orders'.
SELECT
customer_id,
COUNT(order_id) AS total_orders,
MIN(order_date) AS first_order_date
FROM
{{ ref('stg_orders') }} -- This compiles to `your_database.your_schema.stg_orders`
GROUP BY
customer_id
Models can be materialized in different ways:
view: (Default) A SELECT statement stored in the database. The query is re-run every time it's accessed.
table: Persisted as a physical table. Faster to query but uses storage and must be intentionally rebuilt.
incremental: A table that dbt updates by appending or modifying only new records, saving significant compute time.
ephemeral: A common table expression (CTE) that is not materialized in the warehouse but can be referenced by other models.
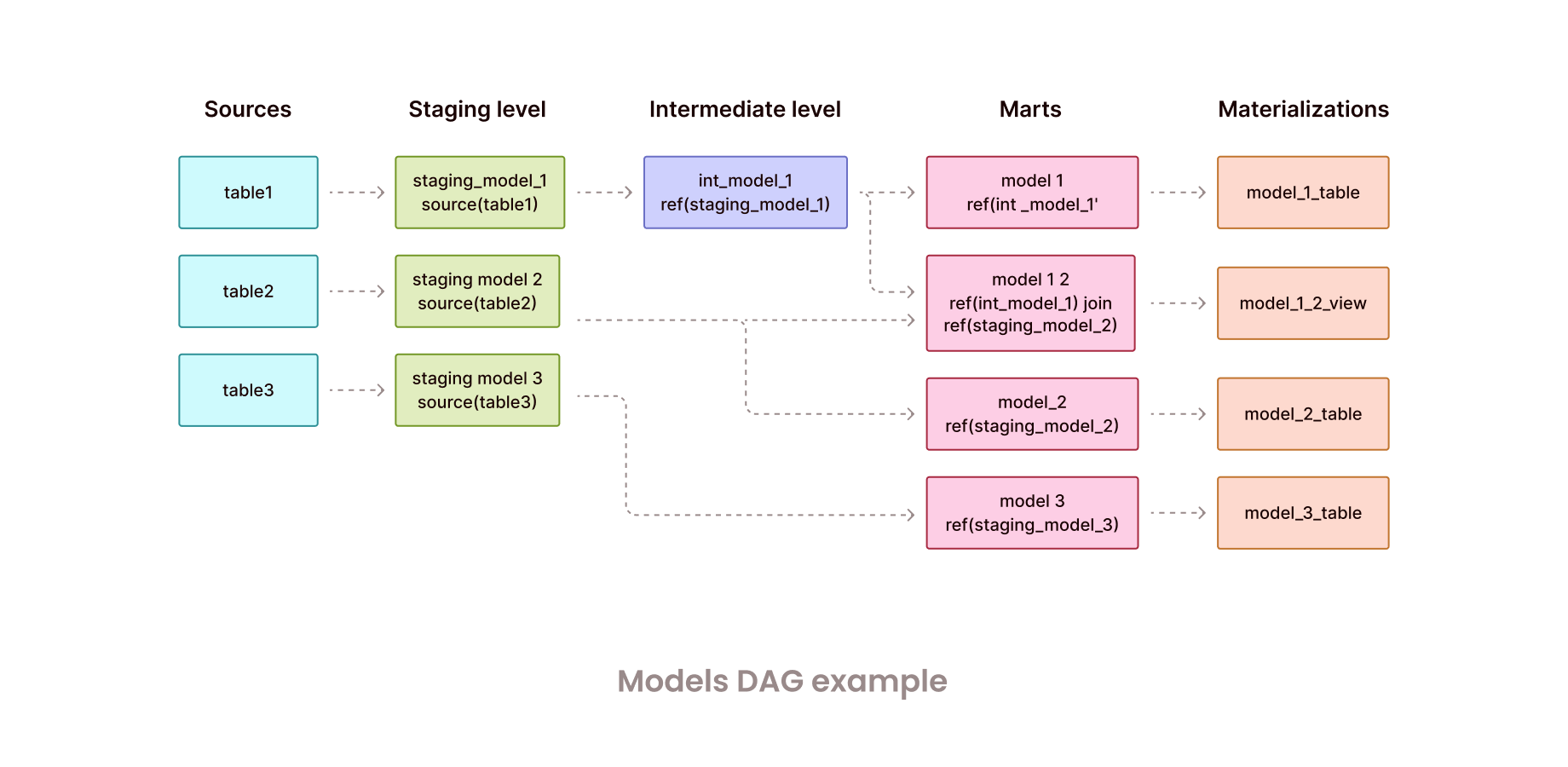
Understanding the DAG
dbt automatically infers the relationships between your models using the ref( ) and builds a DAG (Directed Acyclic Graph).
This means dbt understands the correct order of execution, runs models in parallel when possible, and provides a clear visual lineage of your entire data pipeline. No more guessing how data flows.
Testing: Trusting Your Data
Data quality is fundamental. dbt provides a simple yet powerful framework for testing your data right within your project.
- Schema Tests: Built-in tests you can declare in a
.ymlfile. They are great for quick, common assertions.
not_nulluniqueaccepted_valuesrelationships(referential integrity)
# models/marts/customers.yml
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- not_null
- unique
- Custom (Singular) Tests: A SQL query in the
tests/directory that should return zero rows. If it returns any rows, the test fails. This allows for complex, custom business logic validation.
For example, let's ensure that the total amount recorded for an order in a final fct_orders model matches the sum of its individual line items from a stg_order_items model. A mismatch would indicate a data integrity issue.
-- tests/assert_order_total_matches_line_items.sql
-- This test identifies any orders where the stated total amount
-- does not equal the sum of its constituent line item amounts.
WITH order_line_items AS (
SELECT
order_id,
SUM(item_price * quantity) AS calculated_total
FROM
{{ ref('stg_order_items') }}
GROUP BY
order_id
)
SELECT
ord.order_id,
ord.total_amount AS stated_amount,
oli.calculated_total
FROM
{{ ref('fct_orders') }} AS ord
JOIN
order_line_items AS oli
ON ord.order_id = oli.order_id
WHERE
-- The test will fail if the rounded amounts do not match,
-- which finds potential floating point or calculation errors.
ROUND(ord.total_amount, 2) != ROUND(oli.calculated_total, 2)
Jinja: Supercharging Your SQL
dbt uses the Jinja templating language to make your SQL dynamic and reusable. With Jinja, you can:
- Use control logic like
ifstatements andforloops. - Abstract repeated SQL into macros (reusable functions).
- Set and reference variables to make your project configurable.
-- Use a variable to filter for recent data during development
SELECT *
FROM {{ ref('stg_orders') }}
{% if target.name == 'dev' %}
WHERE order_date >= '{{ var("start_date", "2025-01-01") }}'
{% endif %}
dbt-utils: Don't Reinvent the Wheel dbt-utils is a community-maintained package of macros and tests that solve the most common problems in data transformation (e.g., creating surrogate keys, pivoting columns, unioning tables). It's a must-have for any dbt project.
Install it by adding it to your packages.yml file:
# packages.yml
packages:
- package: dbt-labs/dbt_utils
version: [">=1.0.0", "<2.0.0"]
dbt build: One Command to Rule Them All In a production environment, you'll typically use the dbt build command. It intelligently runs all of your assets in the correct order defined by the DAG:
$ dbt build
This single command will:
- Run your seed files.
- Run your model transformations.
- Run your tests.
- Run your snapshots.
Final Thoughts: Why This Matters for Data Scientists
Learning dbt empowers you to move beyond notebooks and build robust, end-to-end data workflows. It's a mindset shift toward treating data transformation as a rigorous engineering discipline.
For a potential employer, a data scientist with dbt skills is a huge asset. It proves you can:
- Own your data pipelines and build reliable features for modeling.
- Ensure data quality and reproducibility in your experiments.
- Collaborate effectively with data engineers and analysts using a shared framework.
- Build systems that are transparent, versioned, and production-ready.
Ultimately, mastering dbt helps you deliver more value by ensuring the foundation of all your work—the data—is solid.