- Published on
Modern Data Architectures for Data Scientists
- Authors

- Name
- Ashish Thanki
- @ashish__thanki
In today's data-driven world, data scientists sit at the intersection of analytics, engineering, and business strategy. While most are deeply familiar with modelling and experimentation, fewer have a solid grasp of the architectural backbone that powers the data they rely on.
Understanding modern data architectures helps you collaborate better with engineers—and empowers you to design pipelines and experiments that scale. In this post, we'll demystify four major paradigms:
- Lambda Architecture
- Kappa Architecture
- Data Mesh
- Data Fabric
Lambda Architecture: Dual paths for batch and streaming
Lambda architecture separates data processing into batch and streaming layers, each optimized for different requirements.
+----------------+ +-------------------+
| Batch Layer | -----> | |
| (Historical DB)| | |
+----------------+ | |
| Serving Layer | ---> Client Queries
+----------------+ | |
| Speed Layer | -----> | |
| (Real-time | | |
| streaming) | +-------------------+
+----------------+
Architecture Breakdown
- Batch Layer: Stores a full historical dataset in an append-only manner.
- Speed Layer: Processes real-time data for fast, low-latency updates.
- Serving Layer: Combines both views for querying and reporting.
Pros
- High accuracy from batch layer
- Real-time insights from stream layer
Cons
- Two separate codebases (batch and stream).
- Higher maintenance and deployment complexity
Real-world Use Case
Use Lambda when building a fraud detection model that needs real-time alerts (speed layer) and periodic retraining on historical data (batch layer).
Kappa Architecture: Streaming-first simplicity
Kappa simplifies Lambda by treating all data as a stream—even historical data is replayed from logs.
+---------------------+
| Unified Stream (Log)|
+---------------------+
|
v
+----------------------+
| Stream Processing |
| (Stateless or State) |
+----------------------+
|
v
+-------------+
| Query Layer |
+-------------+
Architecture Breakdown
- A single processing layer handles all transformations.
- Data can be reprocessed by replaying the stream.
Pros
- Single codebase
- Lower operational overhead
Cons
- Replay-heavy systems can be expensive
- Not ideal for long, slow historical batch jobs
Real-world Use Case
Perfect for building real-time recommender systems that continuously update with new user behaviour.
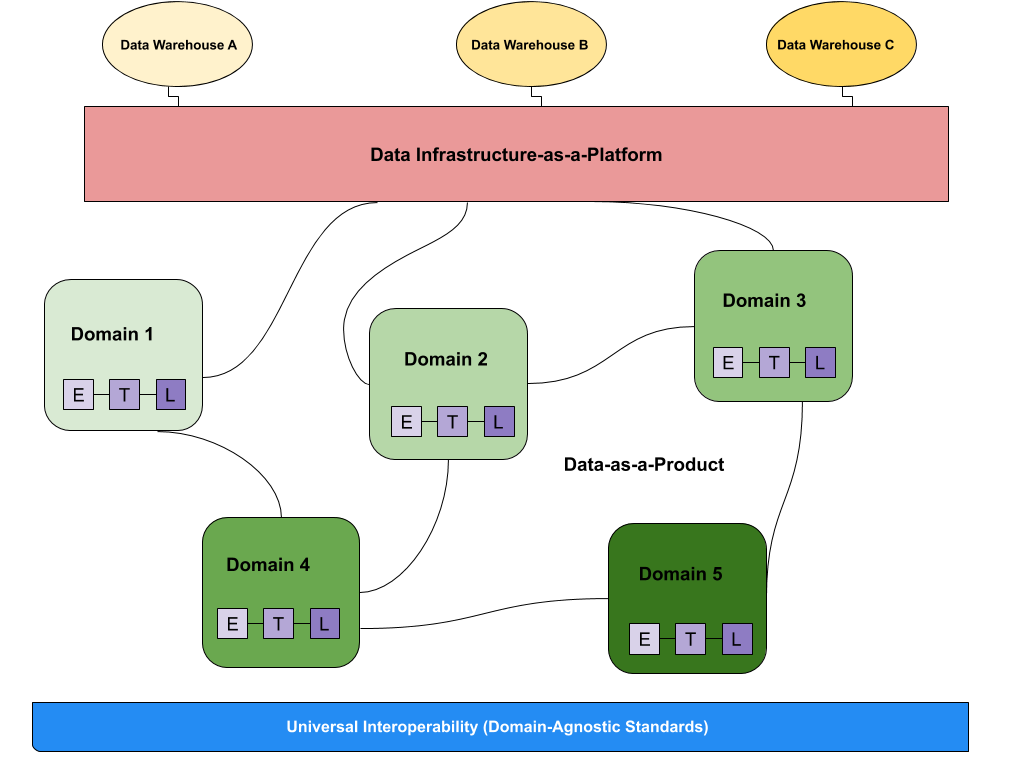
Data Mesh: Decentralizing data ownership
Data Mesh is more about people and process than technology—it promotes treating data like a product, owned by cross-functional domain teams.
+-------------------+ +------------------+ +-------------------+
| Marketing Team | | Sales Team | | Product Team |
| Owns Data + API | | Owns Data + API | | Owns Data + API |
+-------------------+ +------------------+ +-------------------+
\ | /
\ | /
+----------------------------------------+
| Federated Data Platform |
+----------------------------------------+
Key Principles
- Domain-oriented ownership
- Data as a product with SLAs and documentation
- Self-serve data platform
- Federated governance
Pros
- Scales with teams
- Better data quality and understanding
Cons
- High coordination and onboarding cost
- Cultural resistance to change
Real-world Use Case
Marketing owns campaign performance data pipelines, sales owns lead data, and both publish to a shared platform with defined interfaces.
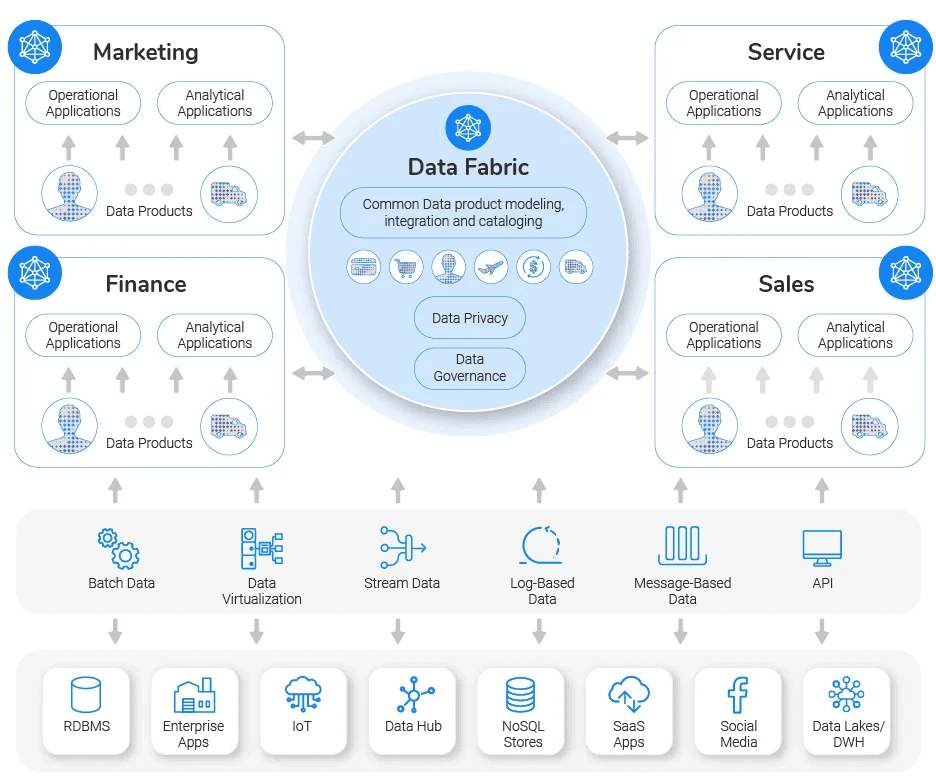
Data Fabric: A connected data layer
Data Fabric is a technical solution that stitches together data sources via metadata and automation—while abstracting away the complexity.
Key Principles
- Unified data access layer
- Metadata-driven integration
- Governance and observability baked in
Pros
- Eliminates data silos
- Works across cloud/on-prem
- Promotes reuse of assets
Cons
- Tooling can be heavyweight
- Needs good metadata management
Real-world Use Case
Model training pipelines can pull clean data from both Snowflake and S3 with unified lineage and quality controls.
Diagram (Data Fabric)
+-------------+ +------------+ +----------------+
| Snowflake | | S3 Bucket | | PostgreSQL DB |
+-------------+ +------------+ +----------------+
\ | /
\ | /
+-------------------------------------------+
| Metadata & Governance Layer |
| (Data Fabric Layer) |
+-------------------------------------------+
|
v
+------------------+
| Consumers |
| (DS / BI / Apps) |
+------------------+
Designing Your Own Hybrid Architecture
No architecture is perfect. Modern data stacks are often hybrid, pulling in the best ideas from each:
| Component | Choice |
|---------------------|-----------------------------|
| Real-time needs | Kappa (Kafka/Flink) |
| Historical jobs | Batch layer (or Delta Lake) |
| Team scalability | Data Mesh |
| Cross-system access | Data Fabric |
Another modern approach is a Lakehouse architecture (e.g., Delta Lake) aim to combine the cost-efficiency of data lakes with the structure of data warehouses—bridging the gap between raw storage and BI-ready data.
Final Thoughts
As a data scientist, you don't need to implement these architectures—but understanding them helps you:
- Build more reliable and scalable pipelines
- Communicate better with data engineers
- Influence the design of systems that power your models
The future of data architecture is modular, streaming-first, and decentralized. And the more you know, the better you can build.